CCR .GB : A G enerative B enchmark for C ompositional C ausal R easoning Evaluation
Causal reasoning and compositional reasoning are two core aspirations in AI. Measuring these behaviors requires principled evaluation methods. Maasch et al. 2025 consider both behaviors simultaneously, under the umbrella of compositional causal reasoning (CCR): the ability to infer how causal measures compose and, equivalently, how causal quantities propagate through graphs. CCR.GB applies the theoretical foundations provided by Maasch et al. 2025 to introduce new community datasets. CCR.GB provides a generative benchmark for measuring CCR at all three levels of Pearl's Causal Hierarchy: (1) associational, (2) interventional, and (3) counterfactual.

Pearl's Causal Hierarchy: observing factual realities, exerting actions to
induce interventional realities, and imagining alternate counterfactual realities
[Bareinboim et al. 2022]. Lower levels underdetermine higher levels. The counterfactual quantity $p(y'_{x'} \mid x,y)$ is known as the probability of necessity.
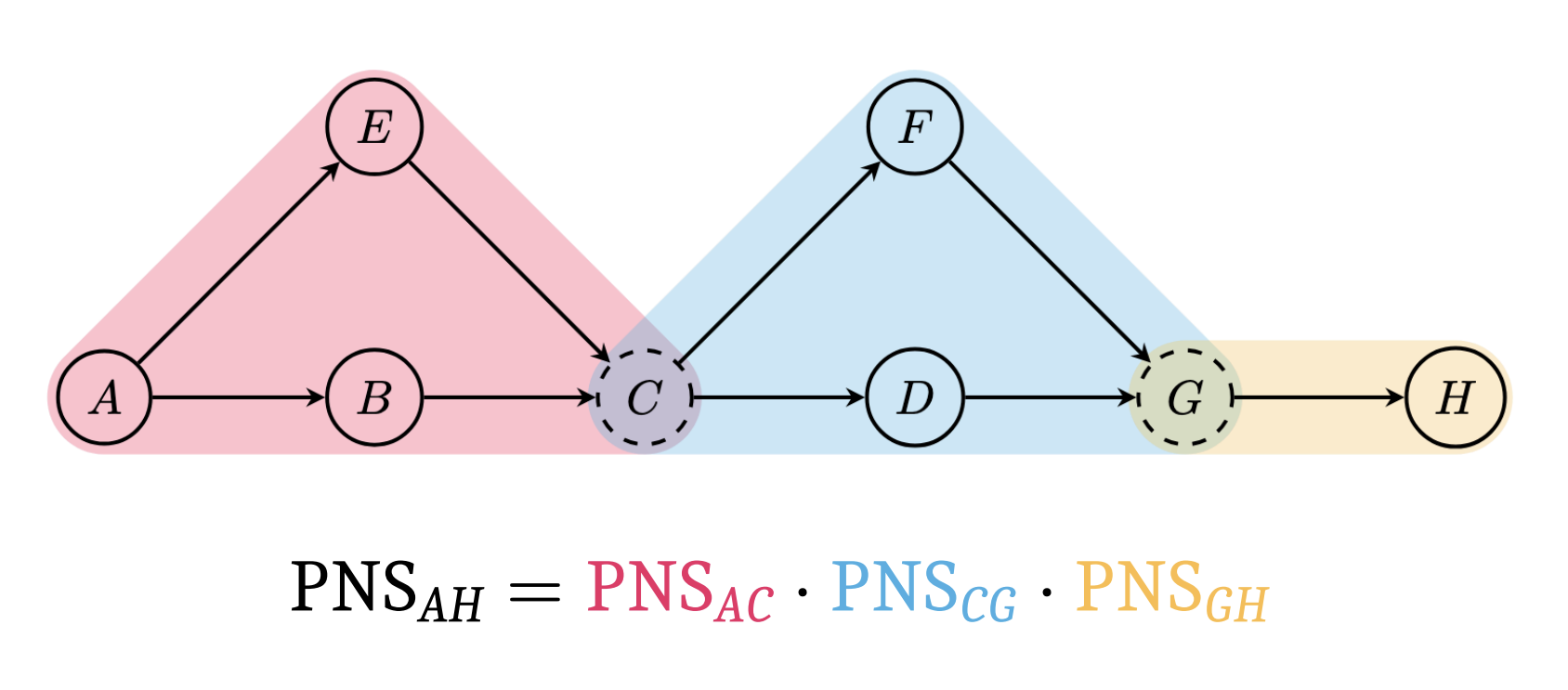
CCR.GB uses a related counterfactual quantity, the probability of necessity and sufficiency, to evaluate AI reasoning
[Pearl 1999].
CCR.GB provides two artifacts:
Random CCR task generator.Open source code for on-demand task generation according to user specifications (graphical complexity, task theme, etc.). Find our task generators on GitHub. We currently offer four themes for random task generation: CandyParty, FluVaccine, FlowerGarden, and ClinicalNotes. The ClinicalNotes theme is currently our most complex prompt setup, and was designed in collaboration with a clinician to loosely resemble real-world history and physical (H&P) notes.Pre-sampled benchmark dataset.A static dataset sampled from the task generator, as a starting point for community benchmarking. Pre-sampled data can be found on Hugging Face. Currently, pre-sampled data are available for the ClinicalNotes and FluVaccine themes on simple causal graphs, but we encourage users to increase the graphical complexity of the tasks they randomly sample.
Future directions. CCR.GB is still under development. Future iterations will consider additional causal estimands and more complex task setups.
Key words. causal reasoning, compositional reasoning, graphical reasoning, clinical reasoning